Services
Formation virtuelle IBM i
Découvrirez comment démarrer avec Watson sur IBM i aujourd'hui
En savoir plusSoutien technique

Au début des années 2000, j’étais responsable de l’analyse de la concurrence pour la plateforme AS/400 d’IBM, devenue ensuite iSeries, puis aujourd’hui IBM i. D’un côté, le travail était simple : montrer qu’IBM offre une technologie supérieure à un coût total de propriété (CTP) inférieur. Mais la difficulté, c’était de faire comprendre au client toutes les variables qui entrent dans le calcul du CTP, surtout quand la concurrence cherchait à en cacher le plus possible.
Un point sur lequel j’insistais toujours – et qui est encore aujourd’hui une force d’IBM i – était le faible coût de propriété se rattachant à son système de gestion de base de données relationnelle (SGBDR) tout équipé. Db2 pour i offre toute la technicité, la performance et la flexibilité des SGBDR les plus coûteux. Et comme il est intégré au système d’exploitation, il automatise bon nombre des tâches banales qui sont inéluctables dans d’autres SGBDR et nécessitent l’embauche d’un administrateur de bases de données (ABD). Les tâches de création et de gestion des espaces de base de données, par exemple, n’existent tout simplement pas avec IBM i.
En tant que responsable de l’analyse de la concurrence pour la plateforme, j’étais ravi de dire à mes clients : « Si vous utilisez IBM i, vous n’avez pas besoin d’un administrateur de base de données. » Je mentionnais souvent le salaire moyen d’un ABD et je l’utilisais dans mon calcul du CTP. Je présentais des diapositives dressant la liste des tâches ennuyeuses que les ABD devaient faire sur d’autres plateformes. Je décrivais un monde où ces administrateurs – des architectes de données, et non plus de simples ABD – pouvaient plutôt se concentrer sur les tâches complexes que sont la définition de l’index parfait pour chaque requête et la création de systèmes dernier cri en matière de schémas entièrement normalisés. C’était le paradis du geek du traitement de données.
Mais dans tout ça, j’oubliais une tâche : la documentation du modèle de données. Je croyais peut-être que les savants architectes s’en occupaient, ou bien les équipes d’applications. Quoi qu’il en soit, jamais je n’ai dit dans mes présentations : « Même sans ABD, il faudra quand même documenter votre modèle de données… et aussi le garder à jour. »
Et je m’en excuse.
Le virage numérique : voilà une stratégie qui donne aux entreprises établies un plan pour surmonter leur montagne de dettes techniques et se réinventer en devenant des innovateurs agiles. Domino’s Pizza, Allstate et UPS figurent parmi les grands noms ayant réussi à le faire.
Leur histoire fascine, car elle pave la voie pour d’autres. Les cas d’entreprises perturbatrices comme Uber et Airbnb sont intéressants, mais dans l’univers des TI, rares sont ceux qui ont la chance de partir de zéro avec des millions en capital de risque.
Les entreprises traditionnelles sont aux prises avec des décennies de dettes techniques, leurs pratiques et leur matériel ne faisant plus le poids contre les applications infonuagiques reposant sur des technologies à code source libre et les méthodes de développement agile.
J’ai d’ailleurs entendu d’un vice-président du développement d’applications : « J’ai hérité d’une plateforme conçue en 1990 avec des technologies des années 1970. » Il exagérait peut-être un peu, mais son problème n’en est pas moins réel : son entreprise doit concurrencer sur un marché hyperaccéléré, tout en portant le fardeau d’une dette technique accumulée sur 20 ou 30 ans.
La première des multiples étapes de l’aventure que constitue un virage numérique : documenter et comprendre l’écosystème de son application. Et pour beaucoup trop de groupes IBM i, il s’agit de documenter leur modèle de données pour la toute première fois. La plupart des groupes ont au minimum une connaissance informelle de l’application, même si pour s’y retrouver, il faut tout un village : tu veux savoir pourquoi le système de paie traite les bonis annuels de cette façon? Va voir Karen, c’est elle qui a créé le module. Tu veux savoir pourquoi l’appel à un fichier se reboucle comme ça? Va voir Joe, il était stagiaire quand le programme a été instauré.
Mais côté modèle de données, seuls les grands groupes pourront expliquer si leur modèle relationnel suit la quatrième forme normale ou un schéma en étoile. Et encore plus rares sont les groupes capables de produire un modèle de données à jour et exact.
Malgré qu’on soit tenté de le faire, il est déconseillé de commencer par afficher les bibliothèques et fichiers dans l’espoir qu’un modèle cohérent naîtra des indices laissés ici et là. Les écosystèmes d’applications sont complexes de nature, avec leurs types de données variés et leurs incohérences dans la dénomination des fichiers. L’enquête humaine ne suffit qu’à faire la moitié du travail, tout au plus.
Heureusement, il existe une solution automatisée : X-Analysis, de Fresche Solutions. Il s’agit d’un ensemble d’outils qui analysent par programme tout l’écosystème d’une application. Le logiciel divise ensuite l’application en ce qu’il appelle des « aires d’application », soit des sections du référentiel interne qui sont déterminées selon l’entreprise, par exemple la gestion des stocks ou l’emplacement des entrepôts. L’utilisateur peut choisir lui-même les aires d’application selon les besoins opérationnels.
Le modèle d’application qui en ressort montre le lien entre les modules et les fichiers, ainsi que le code inutilisé. Plus important encore, on a ainsi documenté le modèle de données.
Que vous utilisiez le standard DDS ou DDL pour vos données, X-Analysis peut reconstruire le modèle complet. Il repère tous les fichiers logiques et physiques ainsi que les liens entre eux : les clés primaires et étrangères. X-Analysis peut vous montrer la dernière fois qu’un fichier précis a été consulté ou téléchargé. Le logiciel fournit aussi le nom au long des tables et colonnes obtenues par extraction intelligente dans les applications existantes qui emploient la base de données; il s’agit là d’une fonction précieuse pour les analystes qui ne possèdent pas les connaissances informelles nécessaires au décodage des champs à 10 caractères (et souvent abrégés à 6!) dans l’application originale.
X-Analysis Advisor, lui, présente les résultats sous forme d’un fichier PDF, que vous pouvez ensuite employer pour donner à tout le monde la même information. Par la suite, il est possible de configurer X-Analysis de sorte qu’il s’exécute périodiquement et fasse la mise à jour continue de la documentation.
En plus de maintenir à jour le modèle de données, X-Analysis le rend aussi interactif pour les développeurs et les ingénieurs des données, qui peuvent y faire un zoom avant. À partir de la vue d’ensemble, il est possible de cliquer sur des tables ou des aires d’application précises et voir ce qui les unit les unes aux autres. On peut même voir les clés primaires et étrangères qui décrivent ces liens.
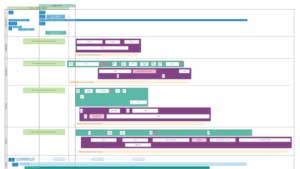
Une fois le travail de X-Analysis accompli, les architectes de données ont accès à ce modèle complet :
 Figure 1 : Modèle de données (eh non, ce n’est pas un test de Rorschach)
Figure 1 : Modèle de données (eh non, ce n’est pas un test de Rorschach)
Si le modèle est déjà intéressant et utile en soi, les équipes peuvent en extraire des renseignements encore plus éloquents grâce au zoom avant. Les analystes peuvent isoler une aire d’application, ce qui ressemblerait à ceci :
 Figure 2 : Aire d’application isolée d’un modèle de données
Figure 2 : Aire d’application isolée d’un modèle de données
Pour comprendre les rapports de dépendance d’une table, l’analyste peut faire un autre zoom avant par simple clic :
 Figure 3 : Rapports de dépendance entre certaines tables
Figure 3 : Rapports de dépendance entre certaines tables
Lorsqu’on utilise X-Analysis, la documentation du modèle de données s’accompagne toujours d’une représentation visuelle de l’application en question. Ces précieux renseignements en main, les équipes peuvent prendre des décisions éclairées sur les prochaines étapes stratégiques de leur virage numérique. Le modèle de données devient l’atout inestimable des utilisateurs et des décideurs pour faire avancer leur entreprise. À plusieurs égards, il s’agit de l’étape la plus importante du parcours de modernisation.
Même si le virage numérique n’est pas un objectif de l’entreprise, il est essentiel d’avoir une documentation garnie de l’écosystème d’applications pour aller de l’avant. Plus la logique métier s’intègre à la couche de base de données par l’utilisation de déclencheurs et de procédures stockées, plus l’importance d’un modèle de données défini de façon stratégique devient capitale.
Toutes mes excuses pour avoir dit « nul besoin d’un administrateur de base de données » – et pas qu’une fois!